前言
标题:LogME: Practical Assessment of Pre-trained Models for Transfer Learning
原文链接:Link
nlp-paper:NLP相关Paper笔记和代码复现
nlp-dialogue:一个开源的全流程对话系统,更新中!
说明:阅读原文时进行相关思想、结构、优缺点,内容进行提炼和记录,原文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
在NLP领域,预训练模型(准确的说应该是预训练语言模型)似乎已经成为各大任务必备的模块了,经常有看到文章称后BERT时代或后XXX时代,分析对比了许多主流模型的优缺点,这些相对而言有些停留在理论层面,可是有时候对于手上正在解决的任务,要用到预训练语言模型时,面对烟火缭乱的语言模型,需要如何挑选合适的模型应用到任务上来。
一个非常直接的方法就是把每一个候选模型针对任务都做一遍微调,因为微调涉及到模型训练,时间至少几个小时起步。有些预训练模型的微调还需要进行超参数搜索,想要决定一个预训练模型的迁移效果就需要将近50个小时!对于没有足够算力的我,苦苦寻觅一个能够高效的选择适合的预训练语言模型的方法,不过资料不好找呀,偶然间我才发现了这篇论文,里面提到的LogME方法值得一试。下图是该方法适配的任务:
多提一下,我这里说的是预训练语言模型,即在适用于NLP领域内的模型选择打分,而对于适用于CV的一些打分方案,像LEEP、NCE、H scores感兴趣的小伙伴可以找论文看看。
本文在LogME方法的相关描述上,组织基于论文作者所在学院的官方公众号上的一篇文章,可直戳原文阅读。原Paper中开源的代码使用Pytorch进行GPU加速,我在本文的最后附上我改成TensorFlow2的代码,方便直接应用在TensorFlow2的相关模型上。
前情提要
将上面提到的问题,描述成图模型,就是论文中所画出如下的这样:
在这个任务中,我们假设有 $M$ 个预训练模型组成的集合 ${\phi_m}^M_{m=1}$ 和 含有 $n$ 个标签的数据集 ${(x_i,y_i)}^n_{i=1}$,正常情况下,我们是通过微调使用各种评判指标作为衡量模型 $\phi$ 的表现 $T_m$,而现在我们想要通过一种方法得到 $S_m$,其中 ${S_m}^M_{m=1}$ 能够与 ${T_m}^M_{m=1}$ 有着很好的相关性。
简单来说就是预训练模型选择问题,就是针对用户给定的数据集,从预训练模型库中选择一个最适合的预训练模型用于迁移学习,核心就是要对每一个预训练模型进行迁移性评估(Transferability Assessment),为每个模型打分,然后选择出打分最高的预训练模型。
LogME方法
LogME的优越性能来自于以下三个方面:
无须梯度计算
为了加速预训练模型选择,我们仅将预训练模型 $\phi$ 视作特征提取器,避免更新预训练模型 $\phi$ 。这样,只需要将预训练模型在给定数据集上前向传播一遍,就可以得到特征 ${f_i=\phi(x_i)}^n_{i=1}$ 和标注 ${y_i}^n_{n=1}$。于是,这个问题就转化成了如何衡量特征和标注之间的关系,也就是说,这些特征能够多大程度上用于预测这些标注。
为此,我们采用一般性的统计方法,用概率密度 $p(y|F)$ 来衡量特征与标注的关系。考虑到微调一般就是在预训练模型的特征提取层之上再加一个线性层,所以我们用一个线性层来建模特征与标注的关系。
说到这里,很多人会想到,一种直观的方法是通过Logistic Regression或者Linear Regression得到最优权重 $w^*$,然后使用似然函数 $p(y|F,w^*)$ 作为打分标准。但是但是这相当于训练一个模型来建模问题,这样容易导致过拟合问题,而且这些方法也有很多超参数需要选择,这使得它们的时间开销很大且效果不好。
无须超参数调优
为了避免超参数进行调优,论文中的方法选用的是统计学中的证据(evidence,也叫marginalized likelihood,即边缘似然)来衡量特征与标注的关系。它不使用某个特定的 $w^*$ 的值,而是使用 $w$ 的分布 $p(w)$ 来得到边缘化似然的值 $p(y|F)=\int p(w)p(y|F,w)dw$。它相当于取遍了所有可能的 $w$ 值,能够更加准确地反映特征与标注的关系,不会有过拟合的问题。其中,$p(w)$ 与 $p(y|F,w)$ 分别由超参数 $\alpha$ 和 $\beta$ 决定,但是它们不需要 grid search,可以通过最大化evidence来直接求解。于是,我们就得到了对数最大证据(Log Maximum Evidence, 缩写LogME)标准来作为预训练模型选择的依据,如下图: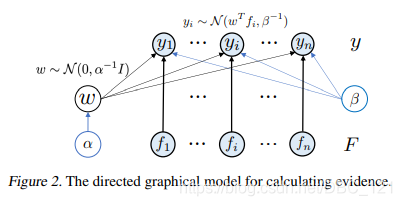
数学推导不在这里赘述了,感兴趣的小伙伴戳原文阅读,该方法的具体细节在下图中给出了,注意,虽然LogME计算过程中将预训练模型视作特征提取器,但是LogME可以用于衡量被用于迁移学习(微调)的性能:
算法实现优化
值得一提的是,LogME算法涉及到很多矩阵分解、求逆、相乘操作,因此一不小心就容易使得算法的复杂度很高(例如上图第9行,粗糙的实现方式)。我们在深入研究该算法后发现,很多矩阵运算的开销可以通过巧妙的计算优化手段大大降低,因此将计算流程优化为上图第10行,整体的计算复杂度降低了一个阶,从四次方降低为三次方(见下表),使得该算法在数秒内就能处理常见情况:
实验结果
在实验部分,我们用合成数据、真实数据等多种方式方式,测试了LogME在17个数据集、14个预训练模型上的效果,LogME在这么多数据集、预训练模型上都表现得很好,展现了它优异的性能。
首先让我们看看,LogME给出的打分标准与人的主观感觉是否一致。我们为分类问题和回归问题分别设计了一个toy实验,使用生成数据来测量LogME的值。从下图中可以看出,不管是分类任务还是回归任务,当特征质量越来越差时,LogME的值也越来越低,说明LogME可以很好地衡量特征与标注的关系,从而作为预训练模型选择的标准: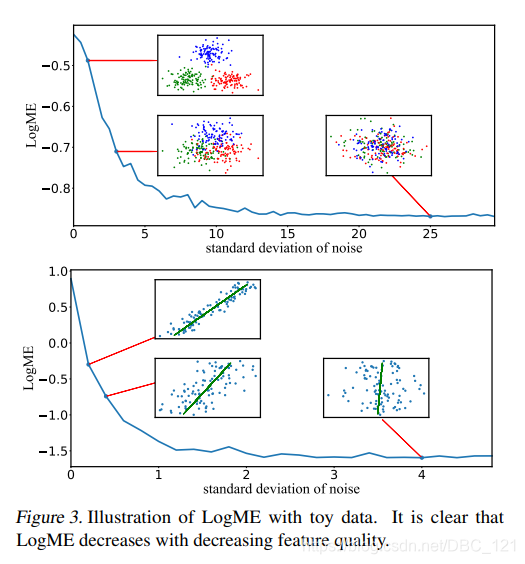
接下来,用LogME来进行预训练模型选择。使用若干个常用预训练模型,通过耗时的微调过程得到它们的迁移性指标,然后衡量LogME与迁移性指标的相关性。相关性指标为加权肯达尔系数 $\tau_w$,它的取值范围是 $[-1,1]$。相关系数为 $\tau_w$ 意味着如果LogME认为预训练模型 $\phi_1$ 比 $\phi_2$ 好,那么 $\phi_1$ 确实比 $\phi_2$ 好的概率是 $\frac{\tau_w+1}{2}$。也就是说,$\tau_w$ 越大越好。
将10个常用预训练模型迁移到9个常见分类数据集中,发现LogME与微调准确率有很高的相关性(见下图),显著优于之前的LEEP和NCE方法。在这几个数据集中,LogME的相关系数 $\tau_w$ 至少有0.5,大部分情况下有0.7或者0.8,也就意味着使用LogME进行预训练模型选择的准确率高达85%或者90%: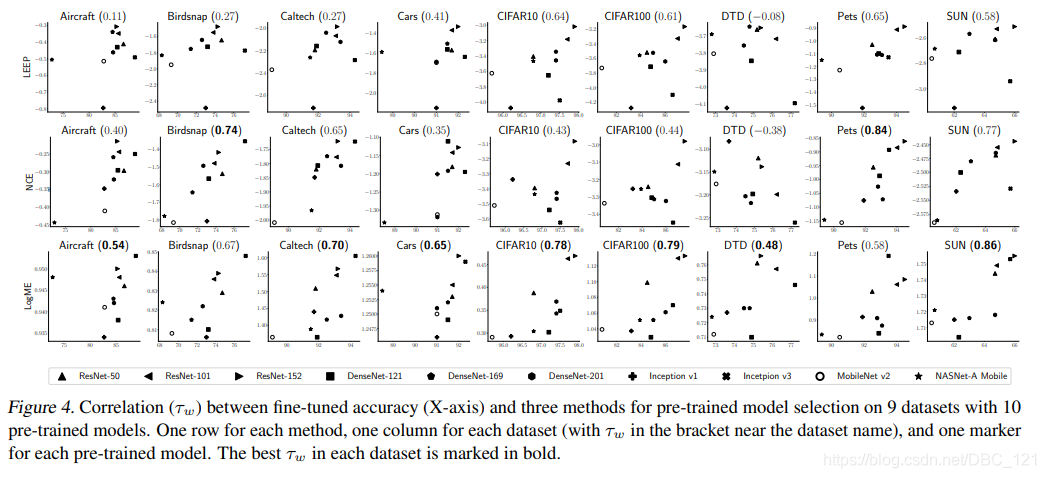
在回归任务的实验中,如下图可以看到LogME与MSE有明显的负相关性,而MSE是越低越好,LogME是越大越好,结果符合预期:
下图可以看到,在五个任务上,LogME完美地预测了四个预训练模型的表现的相对大小,在另外两个任务上的表现也不错。
LogME方法不仅效果好,更难得的是它所需要的时间非常短,可以快速评价预训练模型。如果将直接微调的时间作为基准,LogME只需要0.31‰的时间(注意不是百分号,是千分号),也就是说加速了3000倍!而之前的方法如LEEP和NCE,虽然耗时更少,但是效果很差,适用范围也很有限,完全不如LogME方法: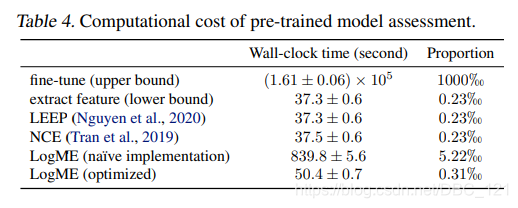
TensorFlow2代码
1 | import tensorflow as tf |