前言
标题:Tacotron和Tacotron2
Tacotron:Tacotron: A Fully End-To-End Text-To-Speech Synthesis Model
Tacotron2:Natural TTS Synthesis By Conditioning Wavenet On Mel Spectrogram Predictions
Github:NLP相关Paper笔记和代码复现
说明:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
本文主要是对Tacotron和Tacotron2论文中的关键部分进行阐述和总结,之所以两篇论文放在一起,是因为方便比较模型结构上的不同点,更清晰的了解Tacotron2因为改进了哪些部分,在性能上表现的比Tacotron更好。
介绍
语音合成系统通常包含多个阶段,例如TTS Frontend,Acoustic model和Vocoder,如下图更直观清晰一点:
构建这些组件通常需要广泛的领域专业知识,并且可能包含脆弱的设计选择。在很多人困扰于繁杂的特征处理的时候,Google推出了Tacotron,一种从文字直接合成语音的端到端的语音合成模型,虽然在效果上相较于传统方法要好,但是相比Wavenet并没有明显的提升(甚至不如Wavenet),不过它更重要的意义在于end-to-end(Wavenet是啥将在后面对比vocoder的时候讲解,顺便提一下Tacotron使用的是Griffin-Lim算法,而Tacotron2使用的是修改版Wavenet)。此外,相较于其他样本级自回归方法合成语音,Tacotron和Tacotron2是在帧级生成语音,因此要快得多。
在传统的Pipeline的统计参数TTS,通常有一个文本前端提取各种语言特征,持续时间模型,声学特征预测模型和基于复杂信号处理的声码器。而端到端的语音合成模型,只需要对文本语音进行简单的处理,就能喂给模型进行学习,极大的减少的人工干预,对文本的处理只需要进行文本规范化以及分词token转换(论文中使用character,不过就语音合成而言,使用Phoneme字典更佳),关于文本规范化(数字、货币、时间、日期转完整单词序列)以及text-to-phoneme可以参见我的另一篇利器:TTS Frontend 中英Text-to-Phoneme Converter,附代码。端到端语音合成系统的优点如下:
- 减少对特征工程的需求
- 更容易适应新数据(不同语言、说话者等)
- 单个模型可能比组合模型更健壮,在组合模型中,每个组件的错误都可能叠加而变得更加复杂
端到端语音合成模型的困难所在:
不同Speaker styles以及不同pronunciations导致的对于给定的输入,模型必须对不同的信号有着更大的健壮性,除此之外Tacotron原本下描述:
TTS is a large-scale inverse problem: a highly compressed source (text) is “decompressed” into audio
上面这句是Tacotron原文中说的,简单来说就是TTS输出是连续的,并且输出序列(音频)通常比输入序列(文本)长得多,导致预测误差迅速累积。想要了解更多关于语音合成的背景知识,可以参考文章Text-to-speech
模型结构
Tacotron
Tacotron的基础架构是Seq2Seq模型,下图是模型的总体架构,该模型包括编码器,基于注意力的解码器和post-processing net,从高层次上讲,模型将字符作为输入,并生成频谱图,然后将其转换为波形。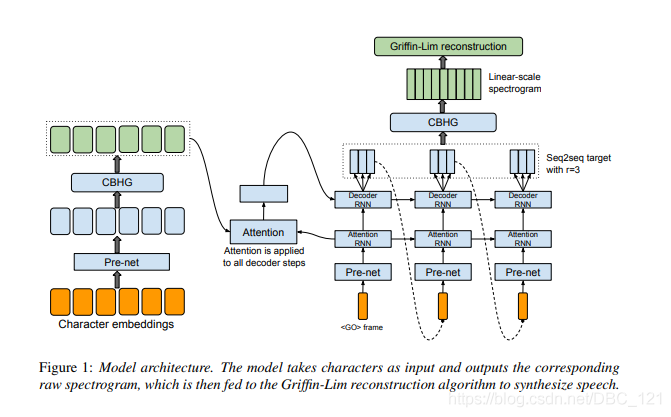
要特别说明的是架构中,raw text经过pre-net后,将会把输出喂给一个叫CBHG的模块以映射为hidden representation,再之后decoder会生成mel-spectrogram frame。所谓CBHG就是作者使用的一种用来从序列中提取高层次特征的模块,如下图所示: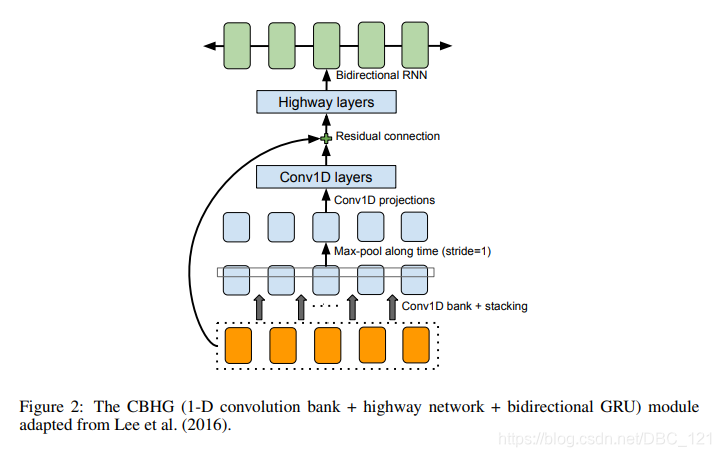
CBHG内部结构说明
CBHG使用了1D卷积、highway、残差链接和双向GRU的组合,输入序列,输出同样也是序列,因此,它从序列中提取表示非常强大。CBHG架构流程如下
- 首先使用 $K$ 组1D卷积对输入序列进行卷积,其中第 $k$ 组表示为 $C_k$ ,卷积的宽度为 $k$(即 $k=1,2,…,K$)。 这些卷积层显式地对本地和上下文信息进行建模(类似于对unigram,bigrams以及K-gram的建模)
- 然后将卷积输出堆叠在一起,并进行最大化池,以增加局部不变性。注意了,最大化池使用stride为1来保留原始时间分辨率
- 接着将处理后的序列传递给一些固定宽度的1D卷积,其输出通过残差连接与原始输入序列相加,同时批量归一化用于所有卷积层
- 然后将输出喂到多层highway网络中以提取高级特征。
- 最后,在顶部堆叠双向GRU RNN,以从前向和后向上下文中提取顺序特征。
在Encoder中,输入被CBHG处理之前还需要经过pre-net进行预处理,作者设计pre-net(pre-net是由全连接层+dropout组成的模块)的意图是让它成为一个bottleneck layer来提升模型的泛化能力,以及加快收敛速度。
Decoder结构说明
随后就是Decoder了,论文中使用两个decoder
- attention decoder:attention decoder用来生成query vector作为attention的输入,交由注意力模块生成context vector
- output decoder:output decoder则将query vector和context vector组合在一起作为输入。
作者并没有选择直接用output decoder来生成spectrogram,而是生成了80-band mel-scale spectrogram,也就是我们之前提到的mel-spectrogram,熟悉信号处理的同学应该知道,spectrogram的size通常是很大的,因此直接生成会非常耗时,而mel-spectrogram虽然损失了信息,但是相比spectrogram就小了很多,且由于它是针对人耳来设计的,因此对最终生成的波形的质量不会有很多影响。
随后使用post-processing network(下面会讲)将seq2seq目标转换为波形,然后使用一个全连接层来预测decoder输出。Decoder中有一个trick就是在每个decoder step预测多个(r个)frame,这样做可以缩减计算量,且作者发现这样做还可以加速模型的收敛。
论文提到scheduled sampling在这里使用会损失音频质量
post-processing net和waveform synthesis
作者使用比较简单的Griffin-Lim 算法来生成最终的波形,由于decoder生成的是mel-spectrogram,因此需要转换成linear-scale spectrogram才能使用Griffin-Lim算法,这里作者同样使用CBHG来完成这个任务。实际上这里post-processing net中的CBHG是可以被替换成其它模块用来生成其它东西的,比如直接生成waveform,在Tacotron2中,CBHG就被替换为Wavenet来直接生成波形。
模型详细的配置
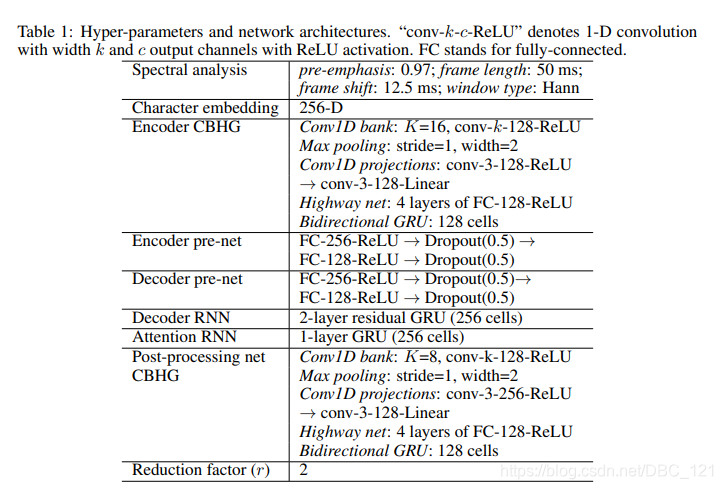
对Decoder和post-processing net使用L1损失,并取平均。作者使用32batch,并将序列padding到最大长度。关于padding的说明,Tacotron原文如下:
It’s a common practice to train sequence models with a loss mask, which masks loss on zero-padded frames. However, we found that models trained this way don’t know when to stop emitting outputs, causing repeated sounds towards the end. One simple trick to get around this problem is to also reconstruct the zero-padded frames.
Tacotron2
Tacotron比较明显的缺点就是生成最终波形的Griffin-Lim算法,Tacotron中作者也提到了,这个算法只是一个简单、临时的neural vocoder的替代,因此要改进Tacotron就需要有一个更好更强大的vocoder。
接下来我们来看看Tacotron2,它的模型大体上分为两个部分:
- 具有注意力的循环序列到序列特征预测网络,该网络根据输入字符序列预测梅尔谱帧的序列
- WaveNet的修改版,可生成以预测的梅尔谱帧为条件的time-domain waveform样本
结构图如下: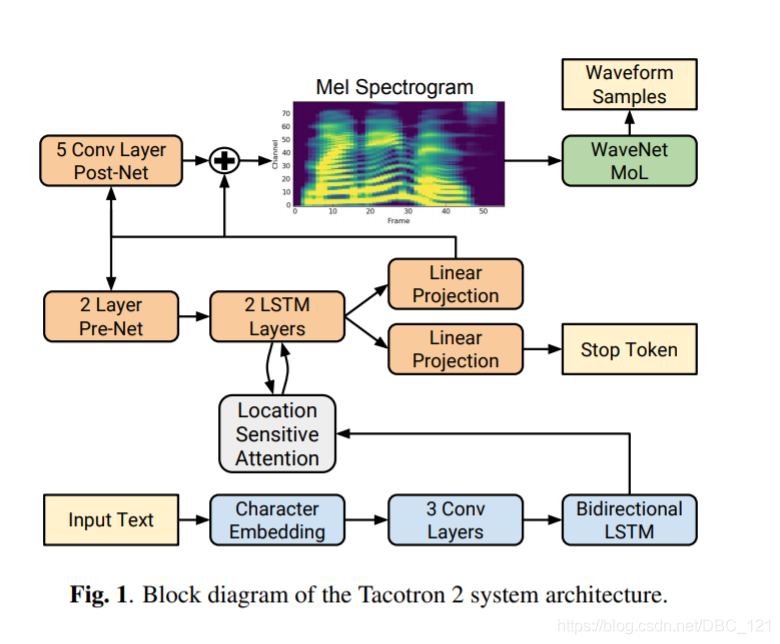
Tacotron2选择预测a low-level acoustic表示,即mel-frequency spectrograms(Tacotron使用 linear-frequency scale spectrograms),Tacotron2原文描述如下:
This representation is also smoother than waveform samples and is easier to train using a squared error loss because it is invariant to phase within each frame.
mel-frequency spectrogram与linear-frequency spectrograms有关,即短时傅立叶变换(STFT)幅度。mel-frequency是通过对STFT的频率轴进行非线性变换而获得的,同时受到人类听觉系统的启发,用较少的维度表示频率内容,原因很好理解,低频中的细节对于音频质量至关重要,而高频中往往包含摩擦音等噪音,因此通常不需要对高频细节建模。
虽然linear spectrograms会丢弃相位信息(因此是有损的),但是诸如Griffin-Lim之类的算法能够估算此丢弃的信息,从而可以通过短时傅立叶逆变换进行时域转换。而mel spectrogram会丢弃更多信息,因此它的逆问题更具有挑战性,这个时候作者想到了WaveNet。
除了Wavenet,Tacotron2和Tacotron的主要不同在于:
- 不使用CBHG,而是使用普通的LSTM和Convolution layer
- decoder每一步只生成一个frame
- 增加post-net,即一个5层CNN来精调mel-spectrogram
实验结果
Tacotron
下图展示Decoder step中,使用不同组件学习到attention alignment的效果: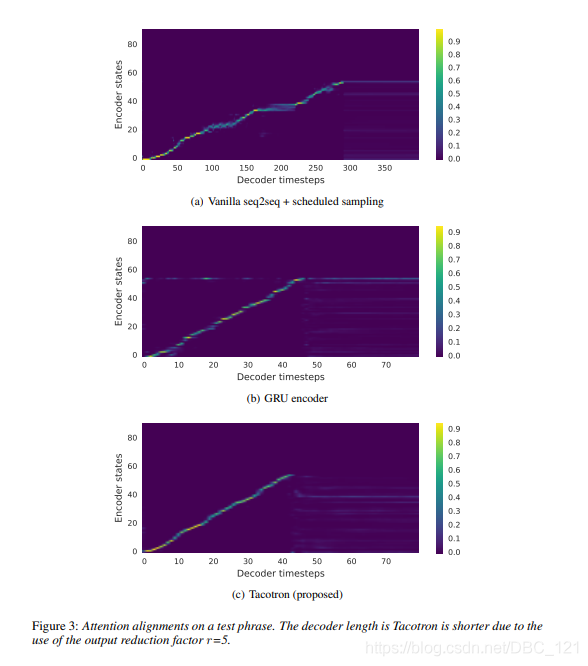
下图展示了post-processing net的实验效果,可以看到有post-processing net的网络效果更好: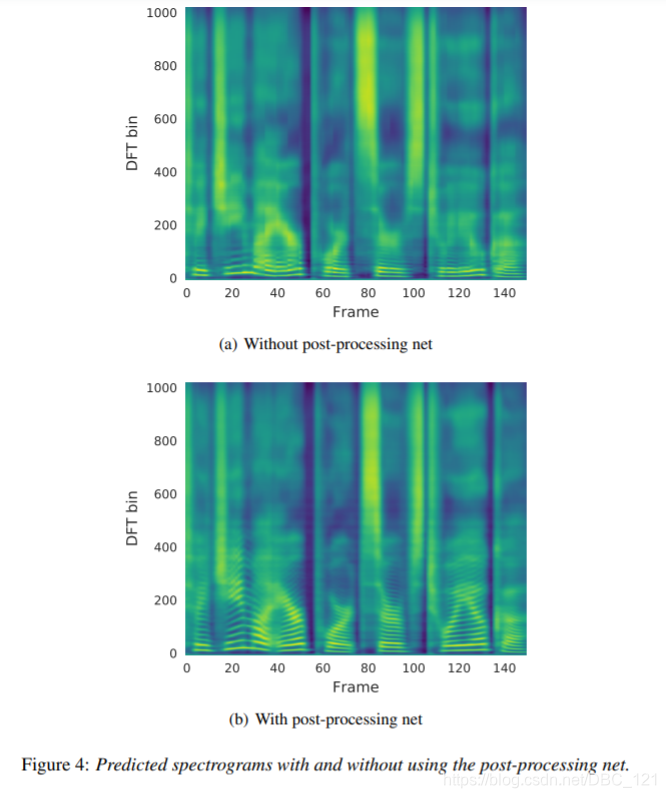
MOS分数对比如下表: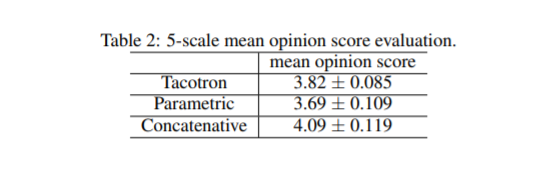
Tacotron2
下表展示了Tacotron2与各种现有系统的MOS分数比较。Tacotron2的分数已经和人类不相上下了,这在很大程度上要归功于Wavenet。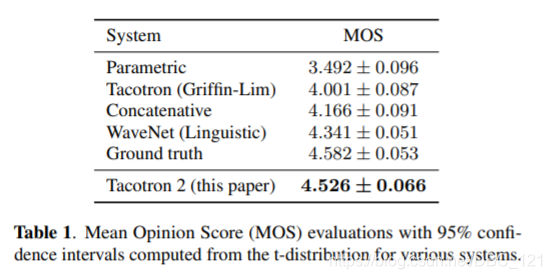
下表是对合成的音频的评价: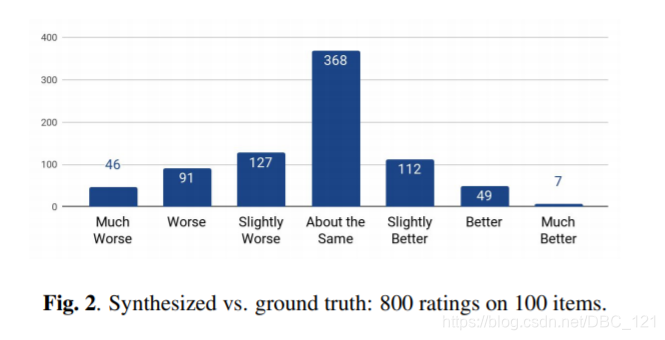
文中提到,Wavenet在这个模型中是和剩下的模型分开训练的,Wavenet的输入是mel-spectrogram,输出是waveform,这个时候就需要考虑输入的mel-spectrogram是选择ground truth,还是选用prediction,作者做了相关实验,结果如下图所示: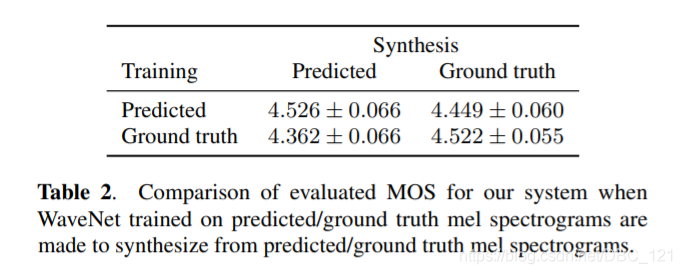
可以看到使用模型生成的mel-spectrogram来训练的Wavenet取得了最好的结果,作者认为这是因为这种做法保证了数据的一致性。下表是生成mel-spectrogram和linear spectrogram的区别(结果证明mel-spectrogram是最好的,同时还能够减少计算,加快inference的时间):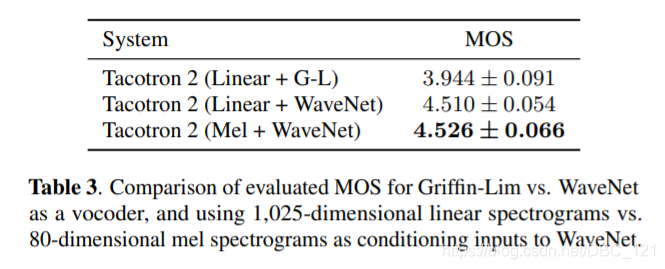
下表是对WaveNet简化之后的MOS分数情况: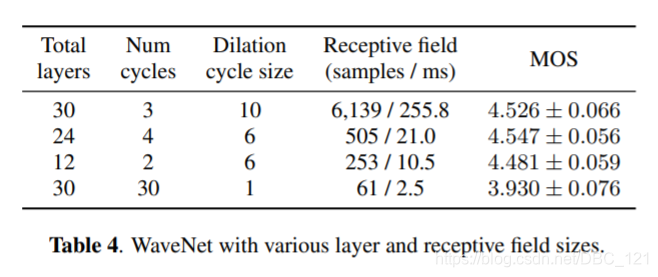
关于vocoder
Tacotron使用的是Griffin-Lim算法,Griffin-Lim是一种声码器,常用于语音合成,用于将语音合成系统生成的声学参数转换成语音波形,这种声码器不需要训练,不需要预知相位谱,而是通过帧与帧之间的关系估计相位信息,从而重建语音波形。更正式一点的解释是Griffin-Lim算法是一种已知幅度谱,未知相位谱,通过迭代生成相位谱,并用已知的幅度谱和计算得出的相位谱,重建语音波形的方法,具体可参考这篇Griffin-Lim 声码器介绍
而Tacotron2使用的WaveNet采用了扩大卷积和因果卷积的方法,让信息随着网络深度增加而成倍增加,可以对原始语音数据进行建模。WaveNet是强大的音频生成模型。 它适用于TTS,但由于其样本级自回归特性而速度较慢。不过要注意的是,WaveNet还需要对现有TTS前端的语言功能进行调整,因此不是端对端的:它仅替代声码器和声学模型。具体可参见如下两篇文章,或参见原论文: