前言
DISTILLING KNOWLEDGE FROM READER TO RETRIEVER FOR QUESTION ANSWERING
nlp-paper:NLP相关Paper笔记和代码复现
nlp-dialogue:一个开源的全流程对话系统,更新中!
说明:阅读原文时进行相关思想、结构、优缺点,内容进行提炼和记录,原文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
开放域问答系统中的Retriever的训练,往往是有监督的,这需要我们为模型提供大量的样本数据,这篇文章利用知识蒸馏的技术,让Retriever去学习Reader的attention score,这样的方法并不需要标注好的query和documents对,换句话说,阅读理解模型的注意力权重可以提供更好的检索模型训练信号。这个模型定位的任务是开放域的问答任务,系统通过知识蒸馏的方法,从大量的非标注的文本中学习到一个“Retriever”模型,然后使用一个“Reader”模型对从“Retriever”模型检索出的文本,计算出Attention Score,从而得到精确的对标文本。
接下来我们来详细了解一下这个系统的具体细节,后文将“Retriever”表述为检索模型,将“Reader”表述为阅读模型。
当前主流的问答系统主要分为几类:FAQ检索型、闲聊型、任务型、知识图谱型、阅读理解型等等。他们之间互相有些区别,但本质上都可以被看作是从庞大的信息中找到想要答案的过程,方法上互相之间也有一些借鉴意义。
对检索式模型感兴趣的小伙伴可以看看百度之前提出的SMN和DAM,我对这两个模型的Paper都有阅读笔记:
DAM
SMN
写在前面
早先的开放域问答系统是将基于TF-IDF的词频算法用作检索模型,并结合阅读模型进行构建的,典型的就是DrQA模型,众所周知,基于词频的检索模型的一大优点就是简单有效,大体上可以归纳为:
- 对于大量文本,可以将所有段落的词频都提前统计出来,并储存为向量的形式
- 对于给定问题,通过向量近邻搜索就可以快速查询到最佳候选段落。
不过文中也指出,使用词频算法的检索模型有着非常明显的局限性,即:
- 词频不能完全表示文本的含义,检索出的文本质量也因此受限,从而影响问答系统整体的表现。
- 基于词频的检索模型不包含注意力机制,很难给关键程度不同的信息以不同的评分
总的来说,单纯基于词频的方式会导致信息检索的依据维度过于片面,而且信息相关性无处体现。自然而然的,我们就会想到使用Language Model来进行相关替换,论文中提到相关的迭代工作如下:
- Vector space model
- Neural information retrieval
- End-to-end retrieval
- Unsupervised learning:这也是与论文的工作最接近的方法,即尝试从无监督的数据中学习信息检索系统。
模型结构
Reader
我们首先来了解
Fusion-in-Decoder
这个模型底层结构是一个sequence-to-sequence模型,由编码器和解码器组成,编码器独立处理不同的文本输入 $(s_k)_{1\leq k\leq n_p}$ 名词短语。在基于Wikipedia的开放域问答中,每个输入 $s_k$ 都是question q和 support passage的concatenation,带有特殊的tokens,形如question:,title:和 context:,分别添加在问题、Wikipedia文章的标题和每篇文章的文本前。然后将编码器的输出表示concatenation起来,形成维度为 $(\sum_kl_k)$ 的全局表示 $X$,其中,$k$ 是第 $k$ 段的长度,$d$ 是模型的嵌入和隐藏表示的大小。然后,解码器将这种表示应用于一个规则的自回归模型、交替的self-attention、cross-attention和feed-forward进行处理。Fusion-in-Decoder模型结构如下: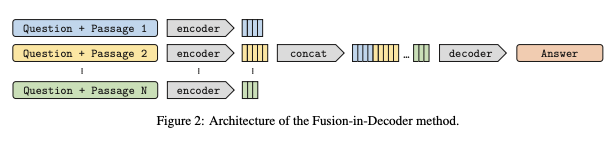
解码器说白了就是使用Transformer中的那套生成信息的结构,这里说明一下Q、K、V的表示形式:
$$Q=W_QH,K=W_KX,V=W_VX$$
后面计算相关系数和注意力分数具体见Transformer,下面我们来通俗的理解一下Reader:
- 阅读模型的打分往往只基于被送入阅读器的段落。想要获得不同段落之间的交互信息,必须将所有候选段落拼接输入阅读器。但由于BERT的复杂度随着序列长度平方级增长,拼接输入并不高效。而Fusion-in-Decoder model中采用生成式(Encoder-Decoder)模型作为阅读模型,他们将不同段落分别输入Encoder获得段落的的表示,然后将这些表示拼接在一起作为Decoder的输入。这样Encoder不需要用平方级的复杂度,Decoder在生成答案的时候也获得了所有段落的信息。
- Reader部分直接沿用了Fusion-in-Decoder模型,通过Fusion-in-Decoder模型检索候选文章输出答案时产生的attention矩阵来指导Retriever进行学习。
- 这其实是一件非常直觉又有趣的事情,Retriever本应该作为Reader的老师,告诉Reader应该看哪些文章,并从中得出答案。但相反,由于Reader已经提前知道了答案,如果Reader阅读范围足够广,我们可以通过attention矩阵来映射Reader在生成答案时把注意力放在了哪些文章上,并以此告诫Retriever,下次召回时应该召回类似的文章。
CROSS-ATTENTION SCORE
根据Fusion-in-Decoder论文提到的,decoder中的cross-attention计算公式如下(上面提到的具体化):
$$Q=W_QH,K=W_KX,V=W_VX$$
$$a_{i,j}=Q_i^TK_j,\ \ \bar{a}{i,j}=\frac{exp(a{i,j})}{\sum_mexp(a_{i,m})},\ \ O_i=W_O\sum_j\bar{a}{i,j}V{i,j}$$
作者假设 $a_{:,j}$ 可以用来度量第 $j$ 个key token对于模型通过value计算下一个特征表示的重要性,并以此作为与该key token对应文档的重要性的代表——the more the tokens in a text segment are attended to, the more relevant the text segment is to answer the question
因此通过对attention score进行聚合,我们可以得到各个Passage的相关性分数 $(G_{q,pk})1\leq k \leq n$,具体来说分数$G$是聚合了decoder中该文档所有key token的pre-attention scores $a_{0,:}$ 得到的。作者比较了不同的mean_max和选取不同层attention score的聚合方法。最后表面简单的对所有层,所有token的attention score作平均效果最佳。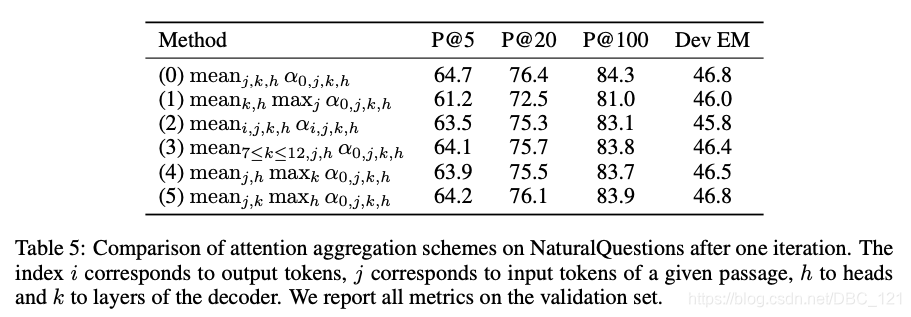
作者通过一个简单的实验证明了 $G_{q,pk}$ 是一个优秀的Passage相关性的评估指标:100篇由DPR召回的文档,使用DPR分数选择前10篇,召回性能从48.2EM降低到了42.9EM,但如果根据 $G_{q,pk}$ 选择前10篇最重要的文档,召回性能仅从48.2EM降低到了46.8EM。
结论:在生成式阅读模型中,Encoder和Decoder的交互注意力权重可看作预测时不同段落信息的重要度。
Retriever
这里我们简单来了解一下DPR模型,再最上面我们有说过基于词频的检索模型的一些明显的缺点,为了解决这类检索模型的缺点,常见的问答系统先通过基于词频的检索模型初筛出较大量候选段落,再应用基于BERT的检索模型,将问题和段落拼接在一起进行精细排序。
然而,这类分阶段检索的模型仍然存在一些问题:它始终需要进过基于词频的检索,有信息损失;每次预测都需要将较大量的文本送入BERT进行精排。能否在一开始就用BERT这类效果更好的模型预先编码好所有段落,在检索的时候直接进行向量搜索呢?
DPR的方法来解决上述缺陷,由于BERT这类模型太过庞大,在预测的时候无法实时对所有段落进行重编码,因而问题和段落需要分开编码。文中采用两个不同的BERT模型分别编码问题和段落,问题和段落编码向量相似度即为检索模型的打分。
DPR的一大创新点在于线下完成所有段落的编码。训练段落编码器时,将含有标准答案字串的候选段落作为编码器的正例,其他段落作为负例。训练完成后,即可在预测前对所有段落进行编码。预测时只需要编码问题,即可通过向量搜索得到相关段落。然而,DPR在监督信息的获取上是存在一定问题的——这也是基于网络的检索模型训练的一大难点。DPR是利用答案字符串是否出现在段落中的信号来定义编码器的正负例,这个信号中包含了大量的噪声。
本文中的Retriever的模型结构设计与DPR相似,只是将两个独立的Bert编码器减少到了一个共享参数的特征编码器。损失函数的设计上,由于Retriever不再是拟合一个二分类问题,而是拟合Reader产生的注意力分布,因此需要最小化 $S_{\theta}(q,p)$ 和 $G_{q,pk}$ 之间的KL散度: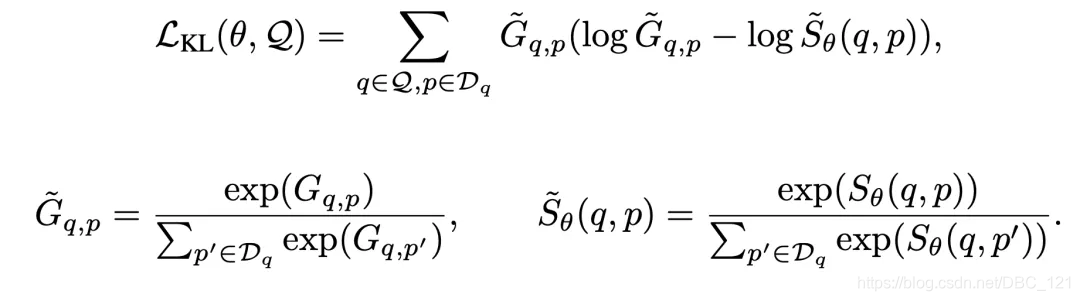
公式中表示Decoder第 $i$ 个token对Encoder第 $j$ 个token,在第 $k$ 层第 $h$ 个注意力头(head)的注意力权重,$G_{q,p}$ 表示的是阅读模型对这个问题,段落对的注意力权重打分,$S_{q,p}$ 表示检索模型对问题是 $q$ 检索出段落 $p$ 的打分,也就是检索模型的输出。这样,我们就可以让检索模型学习阅读模型的注意力信息了。
文中试验了不同的设置,最终确定:Decoder的第0个token对于Encoder同一段落中所有token的注意力权重平均值是最佳设定。同时作者还比较了MSE、max-margin loss等其他损失函数,最终KL散度的训练效果最佳。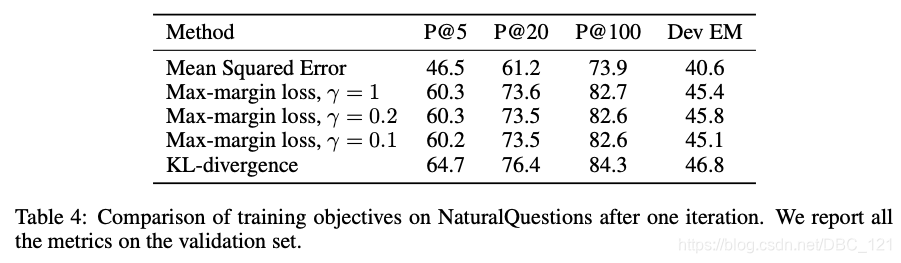
ITERATIVE TRAINING
训练的Pipeline分为4步:
- Train the reader R using the set of support documents for each question $D_q^0$
- Compute aggregated attention scores $(G_{q,p})_{q\in Q,p\in D_q^0}$ with the reader R.
- Train the retriever E using the scores $(G_{q,p})_{q\in Q,p\in D_q^0}$
- Retrieve top-passages with the new trained retriever E
总的来说,就是对于每个问题,用检索模型选取前 $k$ 个相关段落,用于训练阅读模型。在相关段落上训练好阅读模型后,对于每个问题的候选段落计算池化之后的注意力权重。利用注意力权重作为检索模型的蒸馏训练信号,训练检索模型。从随机初始化的检索模型开始训练无疑是效率很低的,初始的候选段落便显得尤为重要。作者选取了不同的初始筛选方法(BM25,BERT,DPR)来确定第一步的相关段落集合。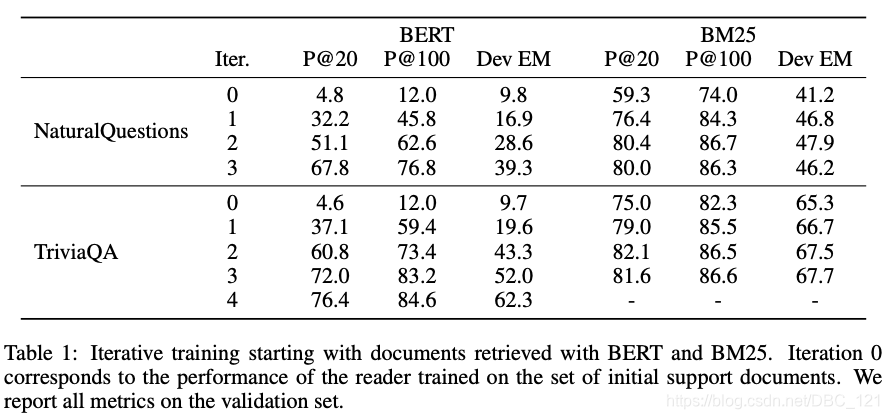
实验发现从DPR方法选择的初始相关段落可以让模型达到最好的效果(从迭代效果来看,实验能够说明这一套迭代的pipeline是有效的)。由于BERT的预训练目标和相关度排序相差甚远,因而用预训练好的BERT作为检索模型的初始参数并选择最初的相关段落集效果不佳。但作者提出的训练方法可以在4个迭代内让检索模型大幅提升效果。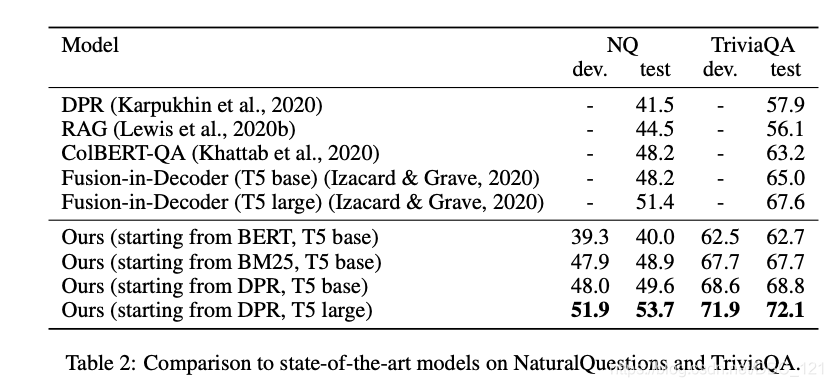
之所以这一套QA循环训练系统不需要给到retriever E标注好的数据对,是因为在训练过程中我们只需要初始化好最开始的support documents集合,通过对R的训练指导E的下一步的召回,即可实现自我迭代。
这里有一个比较关键的地方,在于每轮迭代开始时,重新初始化reader-T5的权重,并保留retriever-Bert的权重继续训练。文章并没有对这样的做法做出解释,猜测有两个作用:
- reader-T5的训练相对于retriever-Bert来说更加容易,尽管我们初始化了reader-T5,但由于retriever-Bert的性能越来越强,召回的文章越来越准确,reader-T5也会更快的收敛,这一定程度上平衡了两个模块的训练进程,防止一方陷入过拟合后导致系统崩溃。
- 通过初始化reader-T5,文章通过监控reader-T5和retriever-Bert的注意力/打分对文章排名的差异性来监控retriever-Bert的训练进程,当reader-T5和retriever-Bert对文章排名结果相近且稳定时,认为系统已经训练充分,停止迭代。
总结
本论文仅使用问题答案样本对就实现了开放域问答的SOTA,这归功于其精彩蒸馏思路将原本两个独立的训练模块Reader和Retriever进行连接,Pipeline的思路减少了模块之间的误差传递,使得整个系统更加一体化。并且文章对于损失函数、初始化方法、attention score的进行了大量的对比实验,组合出了一套完整的训练方案。如果我们把Reader视为精排,Retriever视为召回,这种通过精排模块指导召回模块训练的方法非常值得借鉴。本文从侧面反映了Transformer架构中,attention机制的可解释性,利用模型的attention模块的中间输出,我们可以获取更多其他的有效信息。